 域名頻道IDC知識庫
域名頻道IDC知識庫要使用DeepSeek對私有數據進行訓練,可以遵循以下步驟:
一、數據準備
- 數據收集:收集企業內部的私有數據,這些數據可以包括文檔(如合同、報告、產品手冊)、對話記錄(如客服日志、會議紀要)等。數據格式可以是文本文件(TXT、CSV)、PDF、Word文檔等。
- 數據清洗:去除噪聲數據,如重復內容、無關信息,并對敏感信息進行脫敏處理,如替換人名、電話號碼等。
- 數據標注:對數據進行標注,構建訓練集和驗證集。標注內容包括問答對(Q&A)、文本分類標簽、實體識別標簽等。
- 數據增強:使用差分隱私技術添加噪聲,生成更多訓練樣本。同時,可以通過數據合成工具(如GPT系列模型)生成模擬數據,以增加數據的多樣性。
二、選擇訓練方式
DeepSeek提供了多種訓練方式,企業可以根據自身需求和技術實力選擇適合的方案:
- 云端訓練:將數據上傳到DeepSeek的云端平臺,利用其強大的算力進行訓練。這種方式簡單快捷,適合中小型企業。
- 本地訓練:在企業自己的服務器上進行訓練,確保數據的絕對隱私。適合對數據安全要求極高的企業。
- 混合訓練:結合云端和本地的優勢,部分數據在云端訓練,部分數據在本地微調。
三、模型微調
模型微調是訓練過程中的關鍵步驟,它能讓模型更好地適應企業的特定需求。DeepSeek提供了兩種主要的微調方法:
-
全參數微調(Full Fine-tuning):
- 適用場景:企業私有數據量較大(如超過10GB),且硬件資源充足。
- 方法:加載DeepSeek的基礎模型(如DeepSeek-V3),使用私有數據對模型的所有參數進行微調,并調整超參數(如學習率、批量大小)以優化訓練效果。
- 優點:模型完全適應企業數據,性能最佳。
- 缺點:計算資源消耗大,訓練時間長。
-
參數高效微調(Parameter-Efficient Fine-tuning, PEFT):
- 適用場景:數據量較小或硬件資源有限。
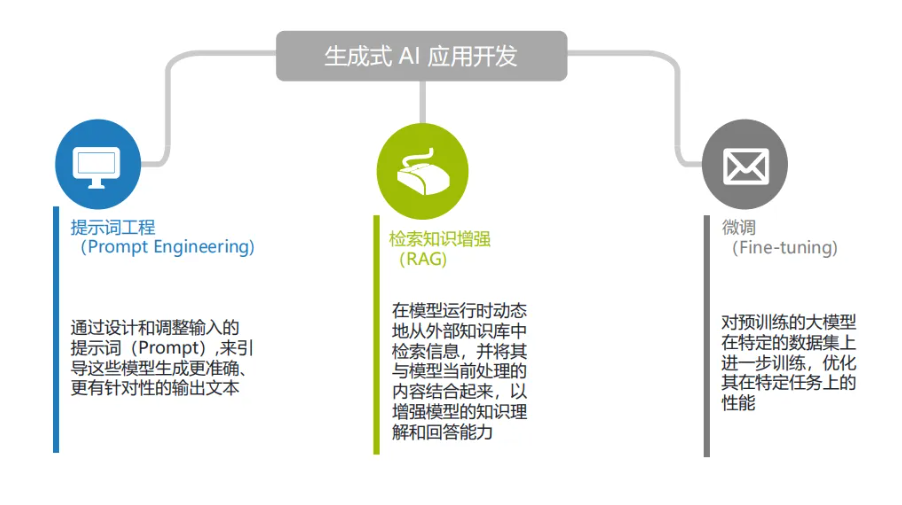
- 方法:在模型的關鍵層(如注意力層)插入低秩矩陣,僅訓練這些矩陣,或者在模型層之間插入小型神經網絡模塊,僅訓練這些模塊。此外,還可以通過設計提示詞(Prompt)引導模型生成特定領域的輸出。
- 優點:訓練速度快,資源消耗低。
- 缺點:性能可能略低于全參數微調。
四、訓練與優化
- 啟動訓練:在DeepSeek平臺上,上傳數據集,選擇合適的模型架構(如BERT、ResNet等),設置訓練參數(如學習率、批次大小等),并啟動訓練。
- 監控訓練過程:使用DeepSeek提供的可視化工具,監控模型訓練過程,分析模型性能。用戶可通過圖表和報告,直觀了解模型的訓練進度和效果。
- 性能優化:根據測試結果,調整模型參數,優化性能。可以嘗試減小批次大小或使用混合精度訓練,以加快訓練速度。同時,增加數據增強的強度或使用正則化技術(如Dropout、L2正則化等)來提高模型的泛化能力。
五、模型部署與應用
- 模型部署:將微調后的模型部署到企業系統中,如智能客服系統、文檔管理系統等。
- 結合其他技術:可以結合檢索增強生成(RAG)和向量數據庫等技術,實現更強大的功能,如智能搜索、實時答案生成等。
- 持續迭代:根據業務發展和用戶反饋,持續更新和優化模型,以保持其性能和適應性。
給您的網站安個家請來域名頻道選擇合適的主頁空間。
我們的機房均提供365天全天候運營服務,專業技術人員負責維護。
VPS主機非常適用于中小企業、小型門戶網站、個人工作室、SOHO一族提供網站空間,較大獨享資源,安全可靠的隔離保證了用戶對于資源的使用和數據的安全。
我已經購買的自己的服務器,服務器托管服務商推薦,五星級服務商推薦詳情鏈接點擊http://www.twrichpower.com/server/ai-server.asp